Table of Contents
What is data ingestion?
How is data ingestion different from data integration?
Data ingestion use case patterns
Common data ingestion challenges
Data ingestion for ETL and ELT
Key data ingestion capabilities
Why Informatica Cloud Mass Ingestion?
Data ingestion customer stories
Get started with unified data ingestion
What is data ingestion?
Data ingestion is the process of moving and replicating data from data sources to destination such as a cloud data lake or cloud data warehouse. Ingest data from databases, files, streaming, change data capture (CDC), applications, IoT, or machine logs into your landing or raw zone. From there, the data can be used for business intelligence and downstream transactions. This enables advanced analytics readiness.

How is data ingestion different from data integration?
Data ingestion is the first step of cloud modernization. It moves and replicates source data into a target landing or raw zone (e.g., cloud data lake) with minimal transformation. Data ingestion works well with real-time streaming and CDC data, which can be used immediately. It requires minimal transformation for data replication and streaming analytics use cases. With data ingestion, companies can increase the availability of all types of data for driving innovation and growth.
Once data is ingested into the landing zone, you need to parse, filter and transform it. This makes it available for advanced analytics and AI usage. At that point, data integration comes in. It helps to transfer and sync different data types and formats between systems and applications. Data integration is not a one-and-done event, but a continuous process. It keeps evolving as business requirements, technologies and frameworks change.
Data ingestion use cases and patterns
Across industries, enterprises are taking advantage of multi-cloud and hybrid-cloud offerings. They want to drive data science and analytics practices for competitive advantage. To achieve this goal, they need to surface all the data types to their users via data ingestion — with any pattern and at any latency.
Let’s explore the various use case patterns data ingestion supports.
Cloud data lake ingestion
Data ingestion solutions enable mass ingestion of data sources into a cloud data lake target. Sources include files, databases, applications, streaming and IoT data. Cloud data lake targets include Amazon Web Services S3 (AWS S3), Google Cloud Storage (GCS), Microsoft Azure Data Lake Storage (ADLS), Microsoft Azure Synapse and Snowflake.
Tip: The speed and quality of the ingestion process correspond with the quality of the cloud data lake. If you ingest your data incorrectly, it can jeopardize the value of the data, resulting in unreliable analytics. Therefore, precise data ingestion is critical for driving AI and machine learning approaches. And it is vital to improving the accuracy of business predictions and spurring innovation.
Cloud modernization
Cloud modernization helps organizations expedite their artificial intelligence and advanced analytics initiatives. This in turn drives critical business decisions and innovation. Organizations embarking on their cloud modernization journey face challenges around legacy data. They also see an increase in disparate data sources and data volume, velocity and integration silos. But one of the biggest roadblocks involves data ingestion and synchronization. These enable organizations to move data and hydrate cloud data lakes and data warehouses from various sources.
A code-free wizard-based data ingestion helps data engineers save time managing ETL by efficiently ingesting databases, files, streaming data and applications. This better handles the scale and complexity of business demands related to data.
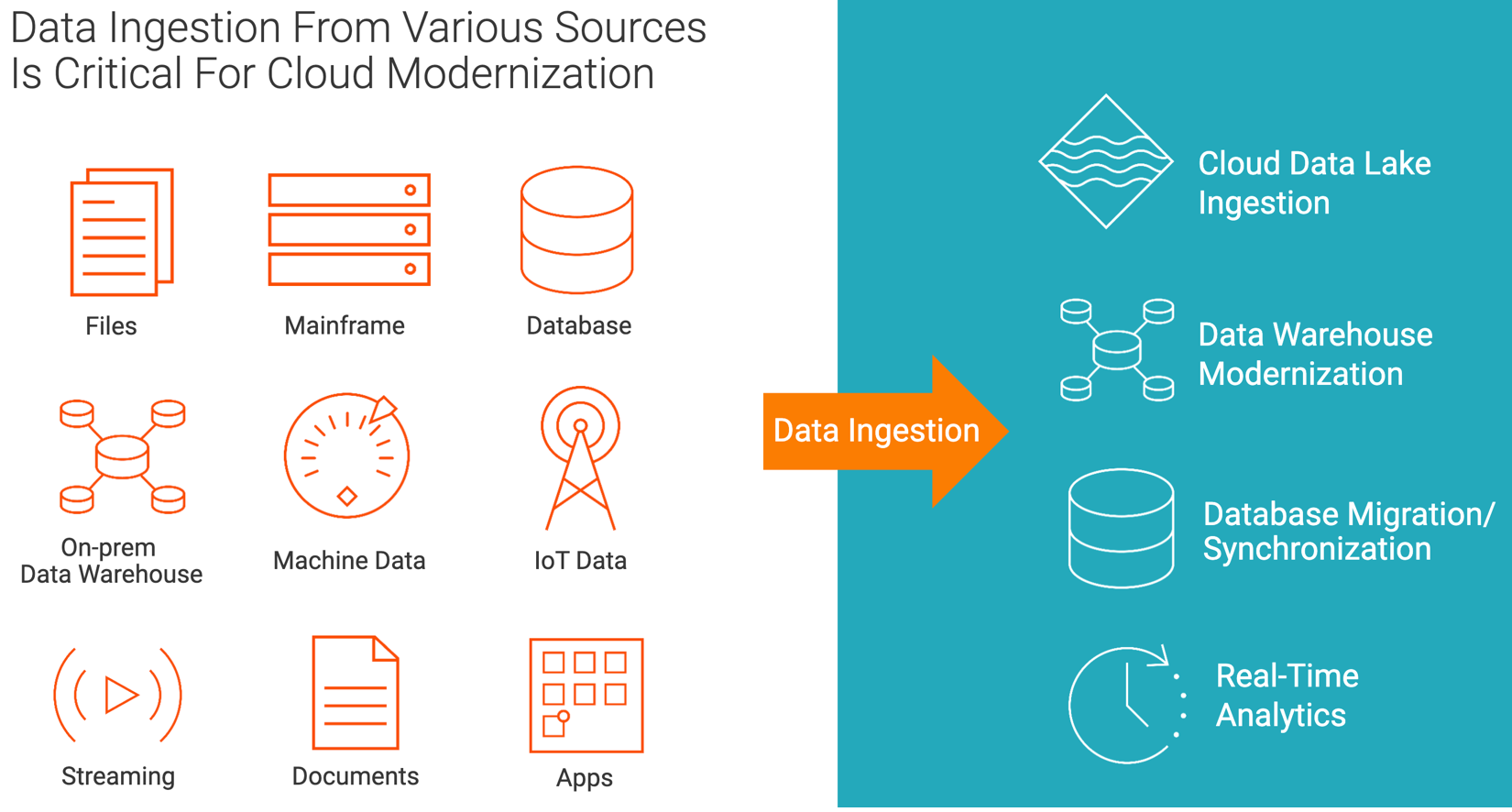
Data ingestion sources and landing zones.
Data ingestion solutions can help accelerate your data warehouse modernization initiatives by mass ingesting on-premises databases (e.g., Oracle, SQL Server, MySQL), data warehouses (e.g., Teradata, Netezza) and mainframe content into a cloud data warehouse (e.g., Amazon Redshift, Databricks Delta Lake, Google BigQuery, Microsoft Azure Synapse and Snowflake).
Tip: It helps to synchronize ingested data with CDC. This enables continuous incremental data replication. It does so by identifying and copying data updates as they take place. Data ingestion with CDC capabilities helps meet today's real-time requirements of modern analytics. This enables faster, more accurate decision-making.
Real-time analytics
Real-time stream processing of events can help unlock new revenue opportunities. For example, real-time processing of customer data can help telecommunications firms improve sales and marketing. In addition, tracking devices with IoT sensors can improve operational efficiency, reduce risk and yield new analytics insights.
Tip: To do real-time analytics, you need to ingest real-time streaming data (e.g., clickstream, IoT, machine logs, social media feeds) into message hubs or streaming targets (e.g., Kafka, Azure Event Hub, Google Pub/Sub). This enables real-time processing while the events are still happening. This real-time data can help improve the accuracy of AI projects.
Data ingestion by platform
Snowflake – Easily ingest and replicate an enormous volume of data at scale from different sources into Snowflake Data Cloud. Sources include application data, mainframes, databases, data warehouses, machine data, IOT, streaming data, logs and files. You can also apply simple data transformation techniques during ingestion to ensure the data is ready for analytics.
Microsoft Azure – Ingest and replicate data at scale from on-premises databases and automatically capture changed data into Azure Synapse for database synchronization and replication use cases.
Amazon Web Services (AWS) – Accelerate advanced analytics and AI and machine learning initiatives by quickly moving data from any SaaS or on-premises data sources into Amazon S3 or AWS Redshift.
Kafka – Drive real-time analytics and streaming CDC use cases by ingesting streaming and IoT data into Kafka with low latency.
Google BigQuery - Efficiently ingest and replicate a large amount of data from on-premises sources into Google Cloud Storage and Google BigQuery with Informatica Cloud Mass Ingestion service. Sources include Oracle, SQL Server, MySQL, Teradata, Netezza and DB2. The service is efficient, secure and scalable, using a simple and intuitive wizard-based approach. It also supports schema drift to automatically detect schema changes in the source database and replicate it into Google Cloud Storage and Google BigQuery as targets.
Databricks Delta Lake - Rapidly load data from databases to Databricks Delta Lake via Database Mass Ingestion. You can move massive amounts of data into Delta Lake in minutes with an easy-to-use, wizard-like user interface.
Salesforce – Ingest data from Salesforce to Snowflake, AWS Redshift, Microsoft Azure Synapse, Google BigQuery, AWS S3, ADLS Gen2, Google Cloud Storage, Databricks and Kafka using Informatica Cloud Mass Ingestion Application for application synchronization use cases.
Watch out for these common data ingestion and synchronization challenges
Businesses are using different approaches to ingest data from a variety of sources into cloud data lakes and warehouses. Sources include traditional databases, data warehouses, mainframe systems, streaming data and machine logs. But despite trying to accelerate their cloud modernization journey, most businesses are struggling.
Here are the key data ingestion challenges hindering cloud modernization initiatives:
Out-of-the-box connectivity to sources and targets
The diversity of data makes it difficult to capture from various on-premises and cloud sources. Many analytics and AI projects fail because data capture is neglected. Building individual connectors for so many data sources isn't feasible. It takes too much time and effort to write all that code. Instead, look for prebuilt, out-of-the-box connectivity to data sources like databases, files, streaming and applications — including initial and CDC load.
Real-time monitoring and lifecycle management
It is incredibly challenging to manually monitor ingestion jobs to detect anomalies in the data and take necessary actions. Instead, be sure to infuse intelligence and automation in your data ingestion process. That way, you can automatically detect ingestion job failure and execute rules for remedial action.
Manual approaches and hand-coding
The global data ecosystem has grown more diverse, and the volume of data has exploded. Under such circumstances, writing custom code to ingest data and manually creating mappings for extracting, cleaning and replicating thousands of database tables can be complex and time-consuming.
Addressing schema drift
One of the biggest challenges of data ingestion is schema drift. Schema drift happens when the schema changes in the source database. If it is not replicated in the target database or data warehouse, it can hamper your workflow.
For example, if you don't address schema drift, data replication can fail, leaving users unable to access real-time data. In addition, data engineers who use hand-coding to build data pipelines must rewrite data ingestion code every time API endpoints or files from your data sources change. This process is time-consuming and unproductive.
Data ingestion for ETL and ELT
Data ingestion, ETL and ELT methods are used interchangeably to collect, migrate and transform data from various distinct sources into the cloud data warehouse. However, data ingestion, ETL and ELT are related concepts. But they are not the same thing. So, let’s look at the difference between these three concepts. How does data ingestion work with ETL and ELT?
In the ETL approach, you use a third-party tool to extract, transform and load the data into an on-premises or cloud data warehouse. This makes it available for downstream analytics.
Using an ELT approach, you use the power of the data warehouse database to perform that transformation.
Data ingestion is critical for ETL and ELT processes to extract or ingest structured and unstructured data from various sources. Then, you can load it into a cloud data warehouse or data lake for further processing. Data ingestion collects, filters and sanitizes the data at low latency, high throughput and continual process. This is true even when the characteristics of the data change. In addition, it replicates the changes from source to target, making sure the data pipeline is up to date.
Choose the right solution: 7 essential data ingestion capabilities
Data ingestion is a core capability for any modern data architecture. A proper data ingestion infrastructure should allow you to ingest any data at any speed. It uses streaming, file, database and application ingestion with comprehensive and high-performance connectivity for batch processing or real-time data.
Below are seven must-have attributes for any data ingestion tool to future-proof your organization:
- Unified experience for data ingestion
- Ability to handle unstructured data and schema drift
- Versatile out-of-the-box connectivity
- High performance
- Wizard-based data ingestion
- Real-time data ingestion
- Cost-efficient
Enterprise data is spread across disparate entities. So, you need a single, unified solution to ingest data from many sources. As data is ingested from remote systems, look for an ingestion solution that can apply simple transformations on the data (e.g., filtering bad records) at the edge. This should be done before it is ingested into the lake.
Many sources emit data in an unstructured form. So, be sure to parse the unstructured data to discover and understand the structure for downstream use. Changes in the structure at the source — often referred to as schema drift — are a key pain point for many organizations. Look for a solution that handles schema drift intelligently. And one that automatically propagates changes to the target systems.
The unified data ingestion solution should offer out-of-the-box connectivity to various sources. This includes files, databases, mainframes, IoT, applications and other streaming sources. Also, it needs to have the capability to persist the enriched data onto various cloud data lakes, data warehouses and messaging systems.
A data-driven culture can only succeed if the data is continuously available. With an efficient data ingestion pipeline, you can cleanse your data or add timestamps during ingestion with no downtime. And you can ingest data in real time using Kappa architecture or batch processing using a Lambda architecture. In addition, you can seek out a data ingestion solution that provides recovery from ingestion job failure. It should have high availability and guarantee exactly one delivery for replication use cases.
You need to be able to ingest data in an efficient way with a wizard-based tool that requires no hand coding. The data should go into a cloud data warehouse with CDC capability. This will ensure you have the most current, consistent data for analytics.
It’s necessary to accelerate the ingestion of real-time log, CDC and clickstream data into Kafka, Microsoft Azure Event Hub, Amazon Kinesis and Google Cloud Pub/Sub. This enables real-time analytics.
Well-designed data ingestion should save your company money by automating processes that are currently costly and time-consuming. In addition, data ingestion can be significantly cheaper if your company isn't paying for the infrastructure or skilled technical resources to support it.
Why Informatica Cloud Mass Ingestion?
With Informatica's comprehensive, cloud-native mass ingestion solution, you get access to a variety of data sources by leveraging more than 10,000 metadata-aware connectors. You can easily access the data to find it and ingest it to where you need it using Cloud Mass Ingestion Files, Cloud Mass Ingestion Streaming and Cloud Mass Ingestion Applications.
Combining that with database and application CDC services will give you the most up-to-date data.
Benefits of Informatica Cloud Mass Ingestion
- Save time and money with a single ingestion solution supporting ingestion for any data, pattern or latency
- Increase business agility with a code-free, wizard-driven approach to data ingestion
- Reduce maintenance costs by efficiently ingesting CDC data from thousands of database tables
- Improve trust in data assets by addressing automatic schema drift and edge transformations
- Improve developer productivity with out-of-the-box connectivity to files, databases, data warehouses, CDC, IoT, streaming and applications sources
- Troubleshoot faster, thanks to real-time monitoring and alerting capabilities
Data ingestion customer stories
KLA moves 12 years of data to the cloud in one weekend
KLA wanted to better service its expanding customer base and satisfy internal demand for analytics. So, they partnered with Informatica and Snowflake to accelerate a cloud-first data strategy. The strategy helped KLA expedite critical reports and enable better-informed decision-making across many core business teams.
Over a single weekend, they moved approximately 1,000 Oracle database tables into Snowflake. These represented 12 years of historical ERP data. KLA combined multiple data sources in the cloud for analysis. As a result, KLA supports more detailed and more user-friendly reporting. Now, their teams can predict demand across complex and often customized product groups.
University of New Orleans (UNO) increases student enrollment and improves retention
Using Informatica Cloud Mass Ingestion, UNO accelerated their cloud modernization journey. They quickly and efficiently migrated thousands of tables with complex data structures from Oracle to Snowflake. And they did it without any hand-coding.
The easy-to-use wizard-based approach helped UNO significantly reduce their manual ETL efforts by 90%. It also helped their developers build predictive models for advanced analytics. This effort helps to improve student recruitment, admission and retention. In addition, UNO plans to ingest CDC data into Snowflake. That will make the latest data from Workday always available in the warehouse.
Get started with unified data ingestion
Cloud Mass Ingestion is the unified ingestion capability of the Informatica Intelligent Data Management Cloud. It is designed to ingest any data on any platform and any cloud as well as multi-cloud and multi-hybrid environments. It allows you to maintain a federated data warehouse and lake by ingesting data in real time. This enables teams across the business to make data-driven decisions.
Register today to try the free 30-day trial of Informatica Cloud Mass Ingestion.




